```markdown





クイックスタート •
仕組み •
検索ツール •
ドキュメント •
設定 •
トラブルシューティング •
ライセンス
Claude-Memは、ツール使用の観察結果を自動的にキャプチャし、セマンティックサマリーを生成し、それらを将来のセッションで利用可能にすることで、セッション間でコンテキストをシームレスに保持します。これにより、Claudeはセッションが終了または再接続した後でも、プロジェクトに関する知識の連続性を維持できます。
---
## クイックスタート
ターミナルで新しいClaude Codeセッションを開始し、以下のコマンドを入力してください:
```
> /plugin marketplace add thedotmack/claude-mem
> /plugin install claude-mem
```
Claude Codeを再起動します。以前のセッションのコンテキストが新しいセッションに自動的に表示されます。
**主な機能:**
- 🧠 **永続的メモリ** - コンテキストがセッション間で保持されます
- 📊 **段階的開示** - トークンコストの可視化を伴う階層的メモリ取得
- 🔍 **スキルベース検索** - mem-searchスキルでプロジェクト履歴をクエリ(約2,250トークン節約)
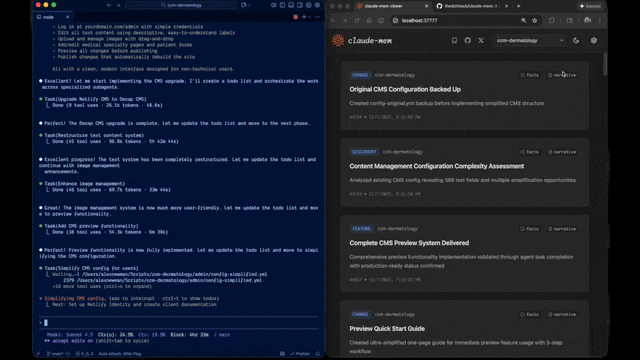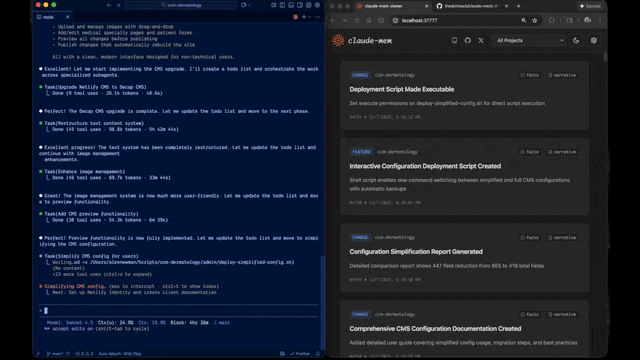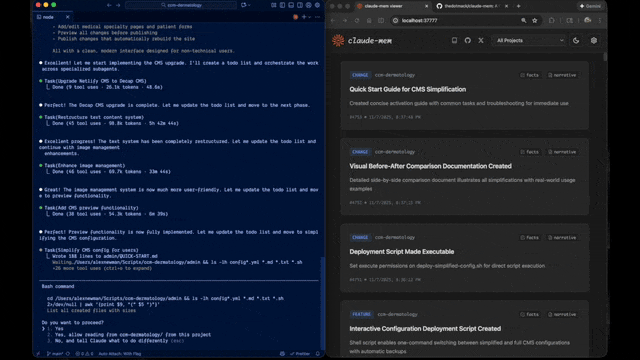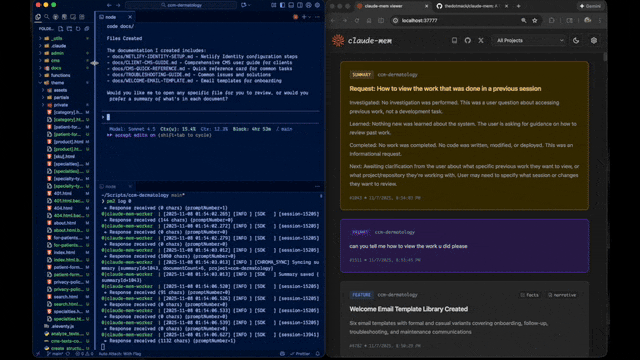
- 🖥️ **Web Viewer UI** - http://localhost:37777でリアルタイムメモリストリーム
- 💻 **Claude Desktopスキル** - Claude Desktopの会話からメモリを検索
- 🔒 **プライバシー制御** - ``タグを使用して機密コンテンツをストレージから除外
- ⚙️ **コンテキスト設定** - どのコンテキストが注入されるかの詳細な制御
- 🤖 **自動動作** - 手動介入不要
- 🔗 **引用** - `claude-mem://` URIで過去の決定を参照
- 🧪 **ベータチャンネル** - バージョン切り替えでEndless Modeなどの実験的機能を試す
---
## ドキュメント
📚 **[完全なドキュメントを表示](docs/)** - GitHubでMarkdownドキュメントを閲覧
💻 **ローカルプレビュー**: Mintlifyドキュメントをローカルで実行:
```bash
cd docs
npx mintlify dev
```
### はじめに
- **[インストールガイド](https://docs.claude-mem.ai/installation)** - クイックスタートと高度なインストール
- **[使用ガイド](https://docs.claude-mem.ai/usage/getting-started)** - Claude-Memの自動動作方法
- **[検索ツール](https://docs.claude-mem.ai/usage/search-tools)** - 自然言語でプロジェクト履歴をクエリ
- **[ベータ機能](https://docs.claude-mem.ai/beta-features)** - Endless Modeなどの実験的機能を試す
### ベストプラクティス
- **[コンテキストエンジニアリング](https://docs.claude-mem.ai/context-engineering)** - AIエージェントコンテキスト最適化の原則
- **[段階的開示](https://docs.claude-mem.ai/progressive-disclosure)** - Claude-Memのコンテキストプライミング戦略の哲学
### アーキテクチャ
- **[概要](https://docs.claude-mem.ai/architecture/overview)** - システムコンポーネントとデータフロー
- **[アーキテクチャの進化](https://docs.claude-mem.ai/architecture-evolution)** - v3からv5への道のり
- **[フックアーキテクチャ](https://docs.claude-mem.ai/hooks-architecture)** - Claude-Memがライフサイクルフックを使用する方法
- **[フックリファレンス](https://docs.claude-mem.ai/architecture/hooks)** - 7つのフックスクリプトの説明
- **[Workerサービス](https://docs.claude-mem.ai/architecture/worker-service)** - HTTP APIとPM2管理
- **[データベース](https://docs.claude-mem.ai/architecture/database)** - SQLiteスキーマとFTS5検索
- **[検索アーキテクチャ](https://docs.claude-mem.ai/architecture/search-architecture)** - Chromaベクターデータベースとのハイブリッド検索
### 設定と開発
- **[設定](https://docs.claude-mem.ai/configuration)** - 環境変数と設定
- **[開発](https://docs.claude-mem.ai/development)** - ビルド、テスト、コントリビュート
- **[トラブルシューティング](https://docs.claude-mem.ai/troubleshooting)** - よくある問題と解決策
---
## 仕組み
```
┌─────────────────────────────────────────────────────────────┐
│ セッション開始 → 最近の観察結果をコンテキストとして注入 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ ユーザープロンプト → セッションを作成、ユーザープロンプトを保存 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ ツール実行 → 観察結果をキャプチャ(Read、Writeなど) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Worker処理 → Claude Agent SDKを使用して学習内容を抽出 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ セッション終了 → サマリーを生成、次のセッションに備える │
└─────────────────────────────────────────────────────────────┘
```
**コアコンポーネント:**
1. **5つのライフサイクルフック** - SessionStart、UserPromptSubmit、PostToolUse、Stop、SessionEnd(6つのフックスクリプト)
2. **スマートインストール** - キャッシュされた依存関係チェッカー(プリフックスクリプト、ライフサイクルフックではありません)
3. **Workerサービス** - Web Viewer UIと10の検索エンドポイントを備えたポート37777のHTTP API、PM2で管理
4. **SQLiteデータベース** - セッション、観察結果、サマリーをFTS5全文検索で保存
5. **mem-searchスキル** - 段階的開示を伴う自然言語クエリ(MCPと比較して約2,250トークン節約)
6. **Chromaベクターデータベース** - インテリジェントなコンテキスト取得のためのハイブリッドセマンティック+キーワード検索
詳細は[アーキテクチャ概要](https://docs.claude-mem.ai/architecture/overview)を参照してください。
---
## mem-searchスキル
Claude-Memは、過去の作業について質問すると自動的に呼び出されるmem-searchスキルを通じてインテリジェントな検索を提供します:
**仕組み:**
- 自然に質問するだけ: *「前回のセッションで何をしましたか?」*または*「このバグを以前修正しましたか?」*
- Claudeは関連するコンテキストを見つけるためにmem-searchスキルを自動的に呼び出します
- MCPアプローチと比較してセッション開始あたり約2,250トークン節約
**利用可能な検索操作:**
1. **観察結果を検索** - 観察結果全体にわたる全文検索
2. **セッションを検索** - セッションサマリー全体にわたる全文検索
3. **プロンプトを検索** - 生のユーザーリクエストを検索
4. **コンセプト別** - コンセプトタグで検索(discovery、problem-solution、patternなど)
5. **ファイル別** - 特定のファイルを参照する観察結果を検索
6. **タイプ別** - タイプで検索(decision、bugfix、feature、refactor、discovery、change)
7. **最近のコンテキスト** - プロジェクトの最近のセッションコンテキストを取得
8. **タイムライン** - 特定の時点の周辺のコンテキストの統一タイムラインを取得
9. **クエリによるタイムライン** - 観察結果を検索し、最適一致の周辺のタイムラインコンテキストを取得
10. **APIヘルプ** - 検索APIドキュメントを取得
**自然言語クエリの例:**
```
「前回のセッションでどんなバグを修正しましたか?」
「認証をどのように実装しましたか?」
「worker-service.tsにどんな変更が加えられましたか?」
「このプロジェクトの最近の作業を見せてください」
「ビューアUIを追加したときに何が起こっていましたか?」
```
詳細な例は[検索ツールガイド](https://docs.claude-mem.ai/usage/search-tools)を参照してください。
---
## ベータ機能とEndless Mode
Claude-Memは実験的機能を備えた**ベータチャンネル**を提供しています。Web Viewer UIから直接安定版とベータ版を切り替えることができます。
### ベータを試す方法
1. http://localhost:37777を開く
2. 設定(歯車アイコン)をクリック
3. **Version Channel**で「Try Beta (Endless Mode)」をクリック
4. Workerの再起動を待つ
バージョンを切り替えてもメモリデータは保持されます。
### Endless Mode(ベータ)
主要なベータ機能は**Endless Mode**です - セッション長を劇的に延長する生体模倣メモリアーキテクチャ:
**問題点**: 標準のClaude Codeセッションは約50回のツール使用後にコンテキスト制限に達します。各ツールは1〜10k+トークンを追加し、Claudeは各応答で以前のすべての出力を再合成します(O(N²)の複雑さ)。
**解決策**: Endless Modeはツール出力を約500トークンの観察結果に圧縮し、トランスクリプトをリアルタイムで変換します:
```
作業メモリ(コンテキスト): 圧縮された観察結果(各約500トークン)
アーカイブメモリ(ディスク): 呼び出しのために保存された完全なツール出力
```
**期待される結果**:
- コンテキストウィンドウで約95%のトークン削減
- コンテキスト枯渇前に約20倍のツール使用
- 二次O(N²)ではなく線形O(N)スケーリング
- 完全な想起のために保存された完全なトランスクリプト
**注意点**: レイテンシーが追加されます(観察生成あたり60〜90秒)、まだ実験段階です。
詳細は[ベータ機能ドキュメント](https://docs.claude-mem.ai/beta-features)を参照してください。
---
## 新機能
**v6.4.9 - コンテキスト設定:**
- コンテキスト注入の詳細な制御のための11の新しい設定
- トークンエコノミクス表示、タイプ/コンセプト別の観察結果フィルタリングを設定
- 観察結果の数と表示するフィールドを制御
**v6.4.0 - デュアルタグプライバシーシステム:**
- ユーザー制御のプライバシーのための``タグ - 機密コンテンツをラップしてストレージから除外
- システムレベルの``タグが再帰的な観察結果の保存を防止
- エッジ処理により、プライベートコンテンツがデータベースに到達しないことを保証
**v6.3.0 - バージョンチャンネル:**
- Web Viewer UIから安定版とベータ版を切り替え
- 手動のgit操作なしでEndless Modeなどの実験的機能を試す
**以前のハイライト:**
- **v6.0.0**: セッション管理とトランスクリプト処理の大幅な改善
- **v5.5.0**: 100%の有効性を持つmem-searchスキルの強化
- **v5.4.0**: スキルベース検索アーキテクチャ(セッションあたり約2,250トークン節約)
- **v5.1.0**: リアルタイム更新を備えたWebベースのビューアUI
- **v5.0.0**: Chromaベクターデータベースとのハイブリッド検索
完全なバージョン履歴は[CHANGELOG.md](CHANGELOG.md)を参照してください。
---
## システム要件
- **Node.js**: 18.0.0以上
- **Claude Code**: プラグインサポート付きの最新バージョン
- **PM2**: プロセスマネージャー(バンドル済み - グローバルインストール不要)
- **SQLite 3**: 永続ストレージ用(バンドル済み)
---
## 主な利点
### 段階的開示コンテキスト
- **階層的メモリ取得**は人間のメモリパターンを反映
- **レイヤー1(インデックス)**: セッション開始時にどの観察結果が存在するかをトークンコストとともに確認
- **レイヤー2(詳細)**: MCP検索を介してオンデマンドで完全なナラティブを取得
- **レイヤー3(完全な想起)**: ソースコードと元のトランスクリプトにアクセス
- **スマートな意思決定**: トークン数により、Claudeが詳細を取得するかコードを読むかを選択できる
- **タイプインジケーター**: 視覚的な手がかり(🔴 重要、🟤 決定、🔵 情報)が観察結果の重要性を強調
### 自動メモリ
- Claudeが起動すると自動的にコンテキストが注入されます
- 手動コマンドや設定は不要
- バックグラウンドで透過的に動作
### 完全な履歴検索
- すべてのセッションと観察結果を検索
- 高速クエリのためのFTS5全文検索
- 引用が特定の観察結果にリンクバック
### 構造化された観察結果
- AI駆動の学習内容抽出
- タイプ別に分類(decision、bugfix、featureなど)
- コンセプトとファイル参照でタグ付け
### マルチプロンプトセッション
- セッションは複数のユーザープロンプトにまたがる
- `/clear`コマンド間でコンテキストが保持される
- 会話スレッド全体を追跡
---
## 設定
設定は`~/.claude-mem/settings.json`で管理されます。ファイルは初回実行時にデフォルト値で自動作成されます。
**利用可能な設定:**
| 設定 | デフォルト | 説明 |
|---------|---------|-------------|
| `CLAUDE_MEM_MODEL` | `claude-haiku-4-5` | 観察結果用のAIモデル |
| `CLAUDE_MEM_WORKER_PORT` | `37777` | Workerサービスポート |
| `CLAUDE_MEM_DATA_DIR` | `~/.claude-mem` | データディレクトリの場所 |
| `CLAUDE_MEM_LOG_LEVEL` | `INFO` | ログの詳細度(DEBUG、INFO、WARN、ERROR、SILENT) |
| `CLAUDE_MEM_PYTHON_VERSION` | `3.13` | chroma-mcp用のPythonバージョン |
| `CLAUDE_CODE_PATH` | _(自動検出)_ | Claude実行ファイルへのパス |
| `CLAUDE_MEM_CONTEXT_OBSERVATIONS` | `50` | SessionStartで注入する観察結果の数 |
**設定管理:**
```bash
# CLIヘルパーで設定を編集
./claude-mem-settings.sh
# または直接編集
nano ~/.claude-mem/settings.json
# 現在の設定を表示
curl http://localhost:37777/api/settings
```
**設定ファイル形式:**
```json
{
"CLAUDE_MEM_MODEL": "claude-haiku-4-5",
"CLAUDE_MEM_WORKER_PORT": "37777",
"CLAUDE_MEM_CONTEXT_OBSERVATIONS": "50"
}
```
詳細は[設定ガイド](https://docs.claude-mem.ai/configuration)を参照してください。
---
## 開発
```bash
# クローンとビルド
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
# テストを実行
npm test
# Workerを起動
npm run worker:start
# ログを表示
npm run worker:logs
```
詳細な手順は[開発ガイド](https://docs.claude-mem.ai/development)を参照してください。
---
## トラブルシューティング
**クイック診断:**
問題が発生した場合は、Claudeに問題を説明してください。トラブルシュートスキルが自動的に起動して診断と修正を提供します。
**よくある問題:**
- Workerが起動しない → `npm run worker:restart`
- コンテキストが表示されない → `npm run test:context`
- データベースの問題 → `sqlite3 ~/.claude-mem/claude-mem.db "PRAGMA integrity_check;"`
- 検索が機能しない → FTS5テーブルが存在するか確認
完全な解決策については[トラブルシューティングガイド](https://docs.claude-mem.ai/troubleshooting)を参照してください。
---
## コントリビュート
コントリビュートを歓迎します! 以下の手順に従ってください:
1. リポジトリをフォーク
2. 機能ブランチを作成
3. テスト付きで変更を行う
4. ドキュメントを更新
5. プルリクエストを提出
コントリビュートワークフローについては[開発ガイド](https://docs.claude-mem.ai/development)を参照してください。
---
## ライセンス
このプロジェクトは**GNU Affero General Public License v3.0**(AGPL-3.0)の下でライセンスされています。
Copyright (C) 2025 Alex Newman (@thedotmack). All rights reserved.
詳細は[LICENSE](LICENSE)ファイルを参照してください。
**これが意味すること:**
- このソフトウェアを自由に使用、変更、配布できます
- ネットワークサーバーで変更してデプロイする場合は、ソースコードを公開する必要があります
- 派生作品もAGPL-3.0の下でライセンスされる必要があります
- このソフトウェアには保証がありません
---
## サポート
- **ドキュメント**: [docs/](docs/)
- **Issue**: [GitHub Issues](https://github.com/thedotmack/claude-mem/issues)
- **リポジトリ**: [github.com/thedotmack/claude-mem](https://github.com/thedotmack/claude-mem)
- **作者**: Alex Newman ([@thedotmack](https://github.com/thedotmack))
---
**Claude Agent SDKで構築** | **Claude Codeで駆動** | **TypeScriptで作成**
---
```