* Refactor code structure for improved readability and maintainability * Add test results for search API and related functionalities - Created test result files for various search-related functionalities, including: - test-11-search-server-changes.json - test-12-context-hook-changes.json - test-13-worker-service-changes.json - test-14-patterns.json - test-15-gotchas.json - test-16-discoveries.json - test-17-all-bugfixes.json - test-18-all-features.json - test-19-all-decisions.json - test-20-session-search.json - test-21-prompt-search.json - test-22-decisions-endpoint.json - test-23-changes-endpoint.json - test-24-how-it-works-endpoint.json - test-25-contextualize-endpoint.json - test-26-timeline-around-observation.json - test-27-multi-param-combo.json - test-28-file-type-combo.json - Each test result file captures specific search failures or outcomes, including issues with undefined properties and successful execution of search queries. - Enhanced documentation of search architecture and testing strategies, ensuring compliance with established guidelines and improving overall search functionality. * feat: Enhance unified search API with catch-all parameters and backward compatibility - Implemented a unified search API at /api/search that accepts catch-all parameters for filtering by type, observation type, concepts, and files. - Maintained backward compatibility by keeping granular endpoints functional while routing through the same infrastructure. - Completed comprehensive testing of search capabilities with real-world query scenarios. fix: Address missing debug output in search API query tests - Flushed PM2 logs and executed search queries to verify functionality. - Diagnosed absence of "Raw Chroma" debug messages in worker logs, indicating potential issues with logging or query processing. refactor: Improve build and deployment pipeline for claude-mem plugin - Successfully built and synced all hooks and services to the marketplace directory. - Ensured all dependencies are installed and up-to-date in the deployment location. feat: Implement hybrid search filters with 90-day recency window - Enhanced search server to apply a 90-day recency filter to Chroma results before categorizing by document type. fix: Correct parameter handling in searchUserPrompts method - Added support for filter-only queries and improved dual-path logic for clarity. refactor: Rename FTS5 method to clarify fallback status - Renamed escapeFTS5 to escapeFTS5_fallback_when_chroma_unavailable to indicate its temporary usage. feat: Introduce contextualize tool for comprehensive project overview - Added a new tool to fetch recent observations, sessions, and user prompts, providing a quick project overview. feat: Add semantic shortcut tools for common search patterns - Implemented 'decisions', 'changes', and 'how_it_works' tools for convenient access to frequently searched observation categories. feat: Unified timeline tool supports anchor and query modes - Combined get_context_timeline and get_timeline_by_query into a single interface for timeline exploration. feat: Unified search tool added to MCP server - New tool queries all memory types simultaneously, providing combined chronological results for improved search efficiency. * Refactor search functionality to clarify FTS5 fallback usage - Updated `worker-service.cjs` to replace FTS5 fallback function with a more descriptive name and improved error handling. - Enhanced documentation in `SKILL.md` to specify the unified API endpoint and clarify the behavior of the search engine, including the conditions under which FTS5 is used. - Modified `search-server.ts` to provide clearer logging and descriptions regarding the fallback to FTS5 when UVX/Python is unavailable. - Renamed and updated the `SessionSearch.ts` methods to reflect the conditions for using FTS5, emphasizing the lack of semantic understanding in fallback scenarios. * feat: Add ID-based fetch endpoints and simplify mem-search skill **Problem:** - Search returns IDs but no way to fetch by ID - Skill documentation was bloated with too many options - Claude wasn't using IDs because we didn't tell it how **Solution:** 1. Added three new HTTP endpoints: - GET /api/observation/:id - GET /api/session/:id - GET /api/prompt/:id 2. Completely rewrote SKILL.md: - Stripped complexity down to essentials - Clear 3-step prescriptive workflow: Search → Review IDs → Fetch by ID - Emphasized ID usage: "The IDs are there for a reason - USE THEM" - Removed confusing multi-endpoint documentation - Kept only unified search with filters **Impact:** - Token efficiency: Claude can now fetch full details only for relevant IDs - Clarity: One clear workflow instead of 10+ options to choose from - Usability: IDs are no longer wasted context - they're actionable 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * chore: Move internal docs to private directory Moved POSTMORTEM and planning docs to ./private to exclude from PR reviews. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * refactor: Remove experimental contextualize endpoint - Removed contextualize MCP tool from search-server (saves ~4KB) - Disabled FTS5 fallback paths in SessionSearch (now vector-first) - Cleaned up CLAUDE.md documentation - Removed contextualize-rewrite-plan.md doc Rationale: - Contextualize is better suited as a skill (LLM-powered) than an endpoint - Search API already provides vector search with configurable limits - Created issue #132 to track future contextualize skill implementation Changes: - src/servers/search-server.ts: Removed contextualize tool definition - src/services/sqlite/SessionSearch.ts: Disabled FTS5 fallback, added deprecation warnings - CLAUDE.md: Cleaned up outdated skill documentation - docs/: Removed contextualize plan document 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * refactor: Complete FTS5 cleanup - remove all deprecated search code This completes the FTS5 cleanup work by removing all commented-out FTS5 search code while preserving database tables for backward compatibility. Changes: - Removed 200+ lines of commented FTS5 search code from SessionSearch.ts - Removed deprecated degraded_search_query__when_uvx_unavailable method - Updated all method documentation to clarify vector-first architecture - Updated class documentation to reflect filter-only query support - Updated CLAUDE.md to remove FTS5 search references - Clarified that FTS5 tables exist for backward compatibility only - Updated "Why SQLite FTS5" section to "Why Vector-First Search" Database impact: NONE - FTS5 tables remain intact for existing installations Search architecture: - ChromaDB: All text-based vector search queries - SQLite: Filter-only queries (date ranges, metadata, no query text) - FTS5 tables: Maintained but unused (backward compatibility) 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * refactor: Remove all FTS5 fallback execution code from search-server Completes the FTS5 cleanup by removing all fallback execution paths that attempted to use FTS5 when ChromaDB was unavailable. Changes: - Removed all FTS5 fallback code execution paths - When ChromaDB fails or is unavailable, return empty results with helpful error messages - Updated all deprecated tool descriptions (search_observations, search_sessions, search_user_prompts) - Changed error messages to indicate FTS5 fallback has been removed - Added installation instructions for UVX/Python when vector search is unavailable - Updated comments from "hybrid search" to "vector-first search" - Removed ~100 lines of dead FTS5 fallback code Database impact: NONE - FTS5 tables remain intact (backward compatibility) Search behavior when ChromaDB unavailable: - Text queries: Return empty results with error explaining ChromaDB is required - Filter-only queries (no text): Continue to work via direct SQLite 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: Address PR 133 review feedback Critical fixes: - Remove contextualize endpoint from worker-service (route + handler) - Fix build script logging to show correct .cjs extension (was .mjs) Documentation improvements: - Add comprehensive FTS5 retention rationale documentation - Include v7.0.0 removal TODO for future cleanup Testing: - Build succeeds with correct output logging - Worker restarts successfully (30th restart) - Contextualize endpoint properly removed (404 response) - Search endpoint verified working This addresses all critical review feedback from PR 133. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> --------- Co-authored-by: Claude <noreply@anthropic.com>
Persistent memory compression system built for Claude Code.
![]()
![]()
![]()
![]()
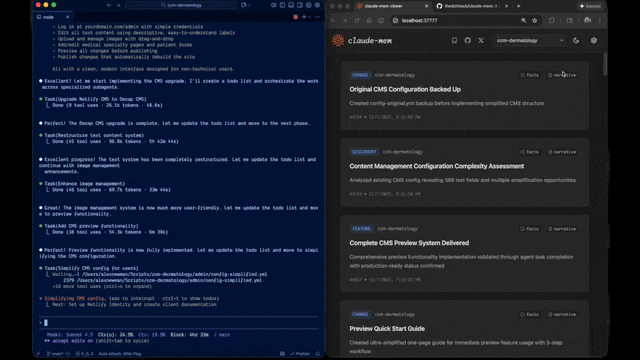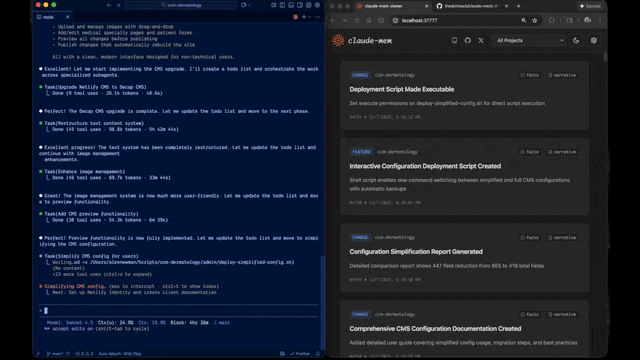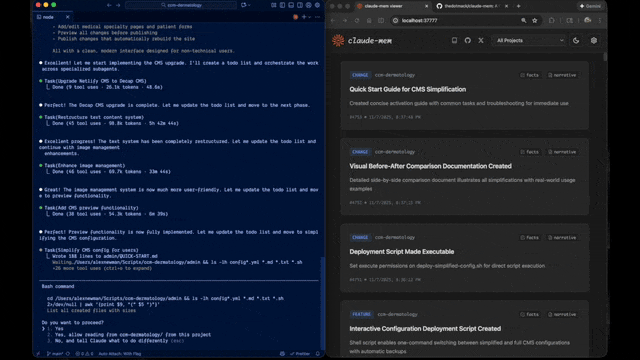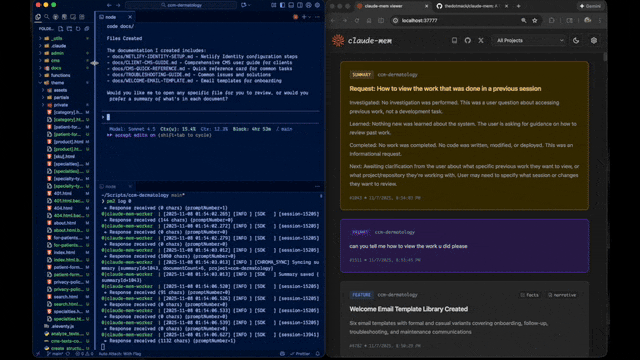
Quick Start • How It Works • Search Tools • Documentation • Configuration • Troubleshooting • License
Claude-Mem seamlessly preserves context across sessions by automatically capturing tool usage observations, generating semantic summaries, and making them available to future sessions. This enables Claude to maintain continuity of knowledge about projects even after sessions end or reconnect.
Quick Start
Start a new Claude Code session in the terminal and enter the following commands:
> /plugin marketplace add thedotmack/claude-mem
> /plugin install claude-mem
Restart Claude Code. Context from previous sessions will automatically appear in new sessions.
Key Features:
- 🧠 Persistent Memory - Context survives across sessions
- 📊 Progressive Disclosure - Layered memory retrieval with token cost visibility
- 🔍 Skill-Based Search - Query your project history with mem-search skill (~2,250 token savings)
- 🖥️ Web Viewer UI - Real-time memory stream at http://localhost:37777
- 🤖 Automatic Operation - No manual intervention required
- 🔗 Citations - Reference past decisions with
claude-mem://URIs
Documentation
📚 View Full Documentation - Browse markdown docs on GitHub
💻 Local Preview: Run Mintlify docs locally:
cd docs
npx mintlify dev
Getting Started
- Installation Guide - Quick start & advanced installation
- Usage Guide - How Claude-Mem works automatically
- Search Tools - Query your project history with natural language
Best Practices
- Context Engineering - AI agent context optimization principles
- Progressive Disclosure - Philosophy behind Claude-Mem's context priming strategy
Architecture
- Overview - System components & data flow
- Architecture Evolution - The journey from v3 to v5
- Hooks Architecture - How Claude-Mem uses lifecycle hooks
- Hooks Reference - 7 hook scripts explained
- Worker Service - HTTP API & PM2 management
- Database - SQLite schema & FTS5 search
- Search Architecture - Hybrid search with Chroma vector database
Configuration & Development
- Configuration - Environment variables & settings
- Development - Building, testing, contributing
- Troubleshooting - Common issues & solutions
How It Works
┌─────────────────────────────────────────────────────────────┐
│ Session Start → Inject recent observations as context │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ User Prompts → Create session, save user prompts │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Tool Executions → Capture observations (Read, Write, etc.) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Worker Processes → Extract learnings via Claude Agent SDK │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Session Ends → Generate summary, ready for next session │
└─────────────────────────────────────────────────────────────┘
Core Components:
- 6 Lifecycle Hooks - context-hook, user-message-hook, new-hook, save-hook, summary-hook, cleanup-hook
- Smart Install - Cached dependency checker (pre-hook script, not a lifecycle hook)
- Worker Service - HTTP API on port 37777 with web viewer UI and 10 search endpoints, managed by PM2
- SQLite Database - Stores sessions, observations, summaries with FTS5 full-text search
- mem-search Skill - Natural language queries with progressive disclosure (~2,250 token savings vs MCP)
- Chroma Vector Database - Hybrid semantic + keyword search for intelligent context retrieval
See Architecture Overview for details.
mem-search Skill
Claude-Mem provides intelligent search through the mem-search skill that auto-invokes when you ask about past work:
How It Works:
- Just ask naturally: "What did we do last session?" or "Did we fix this bug before?"
- Claude automatically invokes the mem-search skill to find relevant context
- ~2,250 token savings per session start vs MCP approach
Available Search Operations:
- Search Observations - Full-text search across observations
- Search Sessions - Full-text search across session summaries
- Search Prompts - Search raw user requests
- By Concept - Find by concept tags (discovery, problem-solution, pattern, etc.)
- By File - Find observations referencing specific files
- By Type - Find by type (decision, bugfix, feature, refactor, discovery, change)
- Recent Context - Get recent session context for a project
- Timeline - Get unified timeline of context around a specific point in time
- Timeline by Query - Search for observations and get timeline context around best match
- API Help - Get search API documentation
Example Natural Language Queries:
"What bugs did we fix last session?"
"How did we implement authentication?"
"What changes were made to worker-service.ts?"
"Show me recent work on this project"
"What was happening when we added the viewer UI?"
See Search Tools Guide for detailed examples.
What's New in v6.0.0
🚀 Major Session Management & Transcript Processing Improvements:
- Enhanced Session Initialization: Accept userPrompt and promptNumber for better context tracking
- Live UserPrompt Updates: Multi-turn conversation support with real-time prompt tracking
- Improved SessionManager: Better context handling and observation processing
- Comprehensive Transcript Processing: New scripts and utilities for analyzing Claude Code transcripts
- Rich Context Extraction: Advanced parsing utilities for extracting meaningful context from sessions
- Refactored Architecture: Improved hooks and SDKAgent for more reliable observation handling
- Silent Debug Logging: Better debugging capabilities without cluttering output
- Enhanced Error Handling: More robust error recovery and debugging tools
Breaking Changes: Significant architectural changes in session management and observation handling. Existing sessions continue to work, but internal APIs have evolved.
Previous Highlights:
- v5.5.0: mem-search skill enhancement with 100% effectiveness rate
- v5.4.0: Skill-based search architecture (~2,250 tokens saved per session)
- v5.1.2: Theme toggle for light/dark mode in viewer UI
- v5.1.0: Web-based viewer UI with real-time updates
- v5.0.3: Smart install caching (2-5s → 10ms)
- v5.0.0: Hybrid search with Chroma vector database
See CHANGELOG.md for complete version history.
System Requirements
- Node.js: 18.0.0 or higher
- Claude Code: Latest version with plugin support
- PM2: Process manager (bundled - no global install required)
- SQLite 3: For persistent storage (bundled)
Key Benefits
Progressive Disclosure Context
- Layered memory retrieval mirrors human memory patterns
- Layer 1 (Index): See what observations exist with token costs at session start
- Layer 2 (Details): Fetch full narratives on-demand via MCP search
- Layer 3 (Perfect Recall): Access source code and original transcripts
- Smart decision-making: Token counts help Claude choose between fetching details or reading code
- Type indicators: Visual cues (🔴 critical, 🟤 decision, 🔵 informational) highlight observation importance
Automatic Memory
- Context automatically injected when Claude starts
- No manual commands or configuration needed
- Works transparently in the background
Full History Search
- Search across all sessions and observations
- FTS5 full-text search for fast queries
- Citations link back to specific observations
Structured Observations
- AI-powered extraction of learnings
- Categorized by type (decision, bugfix, feature, etc.)
- Tagged with concepts and file references
Multi-Prompt Sessions
- Sessions span multiple user prompts
- Context preserved across
/clearcommands - Track entire conversation threads
Configuration
Model Selection:
./claude-mem-settings.sh
Environment Variables:
CLAUDE_MEM_MODEL- AI model for processing (default: claude-sonnet-4-5)CLAUDE_MEM_WORKER_PORT- Worker port (default: 37777)CLAUDE_MEM_DATA_DIR- Data directory override (dev only)
See Configuration Guide for details.
Development
# Clone and build
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
# Run tests
npm test
# Start worker
npm run worker:start
# View logs
npm run worker:logs
See Development Guide for detailed instructions.
Troubleshooting
Quick Diagnostic:
If you're experiencing issues, describe the problem to Claude and the troubleshoot skill will automatically activate to diagnose and provide fixes.
Common Issues:
- Worker not starting →
npm run worker:restart - No context appearing →
npm run test:context - Database issues →
sqlite3 ~/.claude-mem/claude-mem.db "PRAGMA integrity_check;" - Search not working → Check FTS5 tables exist
See Troubleshooting Guide for complete solutions.
Contributing
Contributions are welcome! Please:
- Fork the repository
- Create a feature branch
- Make your changes with tests
- Update documentation
- Submit a Pull Request
See Development Guide for contribution workflow.
License
This project is licensed under the GNU Affero General Public License v3.0 (AGPL-3.0).
Copyright (C) 2025 Alex Newman (@thedotmack). All rights reserved.
See the LICENSE file for full details.
What This Means:
- You can use, modify, and distribute this software freely
- If you modify and deploy on a network server, you must make your source code available
- Derivative works must also be licensed under AGPL-3.0
- There is NO WARRANTY for this software
Support
- Documentation: docs/
- Issues: GitHub Issues
- Repository: github.com/thedotmack/claude-mem
- Author: Alex Newman (@thedotmack)
Built with Claude Agent SDK | Powered by Claude Code | Made with TypeScript